
BACKGROUND
从历史经验来看无状态的服务在可用性、伸缩性方面表现良好,对于无状态的服务来说一个可靠(always available)存储很有必要,很多系统将数据存储在关系型数据库中,但是对于大多数系统来说,这其实不是一个很好的选择:
- 大多数系统需要 Key-Value 接口,不需要 RDBMS 提供的复杂查询
- RDBMS 提供的这些额外功能需要更昂贵的硬件和专业的人员来维护
- 可选的多副本技术有限,通常选择一致性而不是可用性
- RDBMS 扩容很不容易,要通过智能分区来实现负载均衡也不太可能
Dynamo,一种高可用的数据存储技术,提供简单的 Key-Value 接口,高可用性(目标是 Always-On),资源使用效率高,有简单的扩容方案来应对数据量、请求的增长。每个服务都有自己的Dynamo实例。
System Assumptions and Requirements
Query Model: Key-Value 接口,Value 一般小于 1MB
ACID Properties:提供 ACID 保证的存储一般可用性会比较低,Dynamo 的目标用户:可用性 > 一致性。不提供任何隔离性的保证。
Efficiency:对延迟要求较高
Design Considerations
Incremental scalability:节点的增减不应该影响系统的稳定性。
Symmetry:Dynamo 中的每个节点都应该与其对等节点有相同的职责,更易于维护。
Decentralization:相比带中心化控制的系统,系统更简单、更好的可伸缩和可用性。
Heterogeneity:例如:各节点承担的工作可以与各个服务器的性能相关联。场景:不需要升级所有节点就可以扩容一些更高性能的机器。
SYSTEM ARCHITECTURE
System Interface
Put(key, context, value):context 包含了对象的版本信息。
Get(Key):返回与 Key 相关联的对象副本或者多个版本的对象列表以及相关上下文。
Partitioning Algorithm
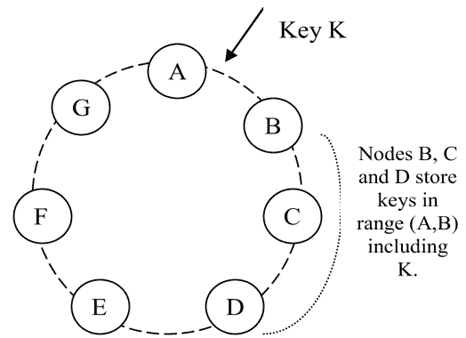
一致性哈希,通过 hash 将数据映射到封闭的环空间上,节点随机的分布在环上,每个节点负责与环上的前一个节点之间的区域。
优点:节点的增删只会影响临近节点
缺点:节点随机分布导致数据、负载分布不均匀,另外忽略了节点性能的差异。
Dynamo 使用了一种变体的一致性哈希,新增了虚拟节点的概念,虚拟节点随机分布在环上,一个节点可以负责多个虚拟节点,使用虚拟节点的优点:
- 如果一个节点变得不可用(由于故障或日常维护),该节点处理的负载均匀地分布在剩余的可用节点上。
- 当一个节点再次可用,或向系统添加一个新节点时,新可用节点从其他每个可用节点接受大致相等的负载。
- 考虑到物理基础设施中的异构性,一个节点负责的虚拟节点数量可以根据其容量决定。
Replication
数据会有多个副本,每个键 key 都被分配给一个节点,节点除了在本地存储每个键外,还在环中的 N-1 后继节点上复制这些 key。
例如:节点 D 将存储范围(A, B)、(B, C)和(C, D)中的键。
负责存储特定 key 的节点组成一个 preference list,为了应对节点故障,preference list 节点数量一般大于 N,
Data Versioning
购物车的场景:即使当前获取到的购物车数据不是最新的,用户往购物车添加商品的操作也不应该被拒绝,而是通过后续合并多版本的数据来解决。
提供最终一致性的保证,数据的更新异步的传播到所有副本。Dynamo将每次修改的结果都视为数据的一个新的、不可变的版本。它允许一个对象的多个版本同时出现在系统中。
使用矢量时钟来确定同一对象不同版本之间的因果关系。矢量时钟实际上是(节点、计数器)对的列表。一个矢量时钟与每个对象的每个版本相关联。通过检查矢量时钟,可以确定两个版本是在平行分支上,还是有一个因果顺序。如果第一个对象时钟上的计数器小于或等于第二个时钟中的所有节点,那么第一个就是第二个时钟的祖先,可以被遗忘。否则,这两项改变被认为是冲突的,需要协调。
读请求会返回不能协调的多版本数据,以及每个版本的上下文,包含了向量时钟信息,写请求需要指定更新的版本。
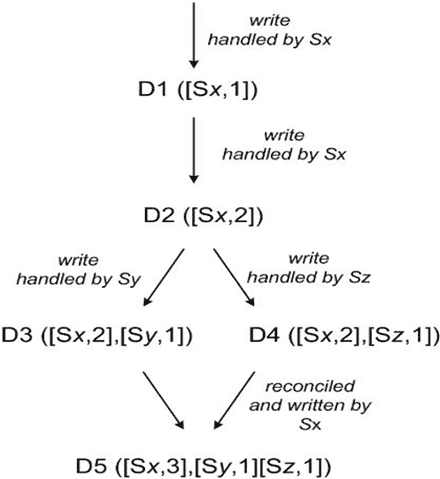
Execution of put/get operations
任何节点都能响应 put/get 请求,实际处理读写请求的节点称为 coordinator,通常为 preference list 的第一个节点。为了保证多副本之间数据的一致性,使用了类 quorum 的一致性协议,R + W > N。
读请求:coordinator 向 preference list 中的前 N 个节点读取数据,R 个节点响应即可。
写请求:coordinator 向 preference list 中的前 N 个节点发送新版本数据,W 个节点响应即可。
Handling Failures: Hinted Handoff
如果使用传统的 quorum 协议,在 Server 异常、网络分区的情况下系统将不可用。Dynamo 采用了一种 sloppy quorum。put/get 不是在在 preference list 中的前 N 个节点进行,而是在前 N 个健康节点进行。
例如:节点 A 故障期间,本应由节点 A 负责的数据的请求可以由 D 来负责,检测到 A 恢复后,D 将数据复制到 A 并删除本地的数据。
Handling permanent failures: Replica synchronization
大多是情况下节点故障恢复时间比较短,Hinted Handoff 能正常工作。有些时候在故障节点恢复之前,Hinted replicas 也变的不可用了。为了解决这种问题,Dynamo 实现了 anti-entropy 来保证多个副本数据的同步。
Dynamo 会为每个 virtual node 独立维护一个 Merkel tree,使用 Merkel trees 来快速检测副本的不一致,在 Merkel tree 中每个节点维护了它所有子节点的 hash。
检测 virtual node 数据一致性、数据同步时机?
Membership and Failure Detection
Ring Membership
节点的故障通常是暂时的,大部分不会持续很长时间,所以不应该触发分区的重新分配、副本的修复,手工误操作也是同样的问题。采用控制工具人工主动从集群中增删节点。
- 连接到某一节点进行集群节点的变更。
- 服务节点变更请求的节点将数据持久化并通过 gossip 协议逐步扩散到整个集群。
External Discovery
上述机制有可能导致逻辑分区,选择某些节点充当种子节点,所有节点最终都会与种子节点同步 membership。
Failure Detection
为了避免 put/get/partition 传输等过程中对故障节点无意义的重试。
如果某节点 B 不响应请求,则可认为 B 故障,则将请求发送到 B 的备用节点。
如果 Client 稳定的进行 put/get 请求时,能快速的发现故障节点。
Adding/Remoing Storage Nodes
新增一个节点时,随机分配一些 token,当前负责处理相应 token 范围数据的节点需要将数据迁移到新节点。
Problem | Technique | Advantage |
Partitioning | Consistent Hashing | Incremental Scalability |
High Abailability for writes | Vector clocks with reconciliation during reads | Version size is decoupled from update rates。 |
Handing temporary failures | Sloppy Quotum and hinted handoff | 当某些副本不可用时,提供高可用性和持久性保证。 |
Recovering from permanent failures | Anti-enttopy using Merkle trees. | 后台同步不一致的副本。 |
Membership and failure detection | Gossip-based membership protocol and failure detection. | 保证节点的对等性,避免中心节点存储。 |
IMPLEMNTATION
每个存储节点包含三个重要组件:请求协调、成员关系维护、故障检测。另外还有一个本地持久化组件,支持多种存储引擎。
请求协调:
- 代表 client 执行读写请求,从一个或多个节点收集数据,将数据持久化到一个或多个节点。
- 每个请求都会建立一个独立的状态机。各个阶段
写请求由前 N 个节点之一负责,始终由第一个节点来处理的话可以将所有写操作都序列化,但是有可能导致负载不均衡。由于每个读操作通常会跟一个写操作,所以上个读请求响应最快的节点优先作为写操作的协调器。
EXPERIENCES & LESSONS LEARENED
Dynamo 被多个具有不同配置的服务使用。区别主要在多版本的协调逻辑、quorum R/W配置。常见的 Dynamo 使用模式:
- 基于特定业务逻辑的版本协调:由 Client 进行版本协调。比如购物车的场景,Client 可以将购物车多个版本的的内容进行合并。
- 基于时间戳多版本协调:由系统执行基于时间戳的协调逻辑,选择物理时间戳值最大的对象作为正确版本。场景:维护 session 信息的服务。
- 高性能读取引擎:更新较少,但是读取吞吐很高。在这种配置中,R通常设置为1,W设置为n。
Dynamo 的主要优点是它的客户端应用程序可以通过调整N、R和W的值,来在性能、可用性和持久性之间做权衡。常见的(N,R,W)配置是(3,2,2)。
Blancing Performance and Durability
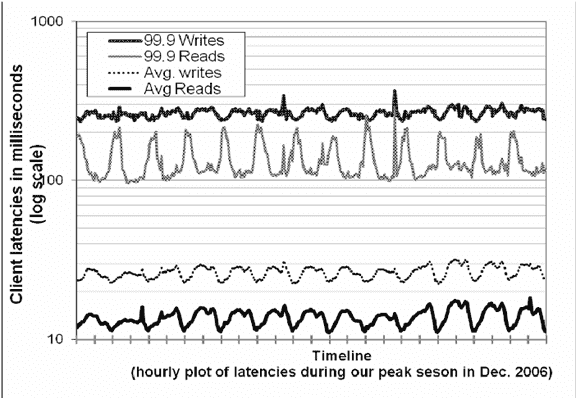
瓶颈主要在磁盘 IO,系统吞吐、耗时都存在波峰波谷,请求响应耗时 99.9 分位比 avg 高出了一个数量级。
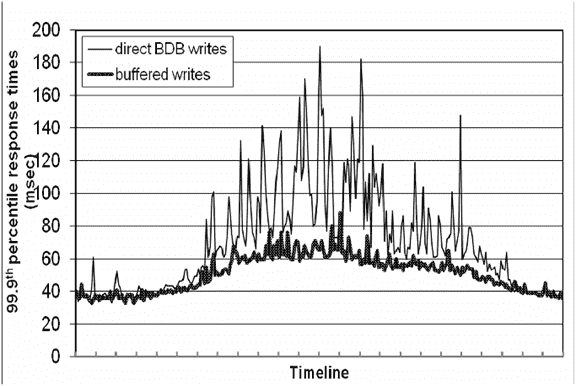
为了优化耗时,节点在内存中维护缓存区,写请求只写缓存,后台线程异步刷盘。为了降低服务器宕机导致的数据丢失风险,会在 N 个副本中选一个执行同步写,既能保证写操作性能,又降低了数据丢失风险。
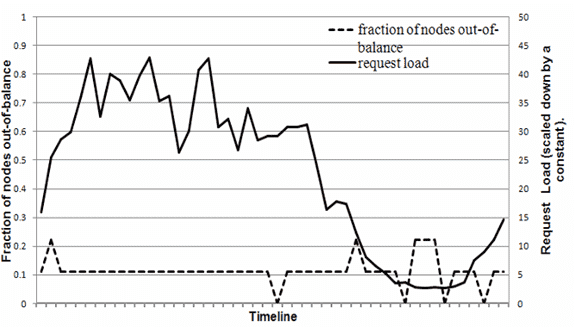
节点的负载与系统平均负载的差值小于一定阈值则节点是 in-blance 的,负责节点就是 out-of-blance 的。
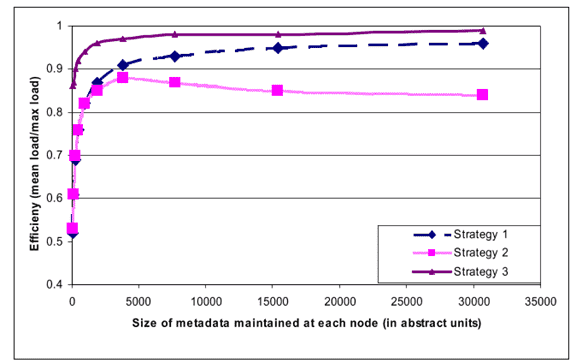
Dynamo partition 策略的演进历程
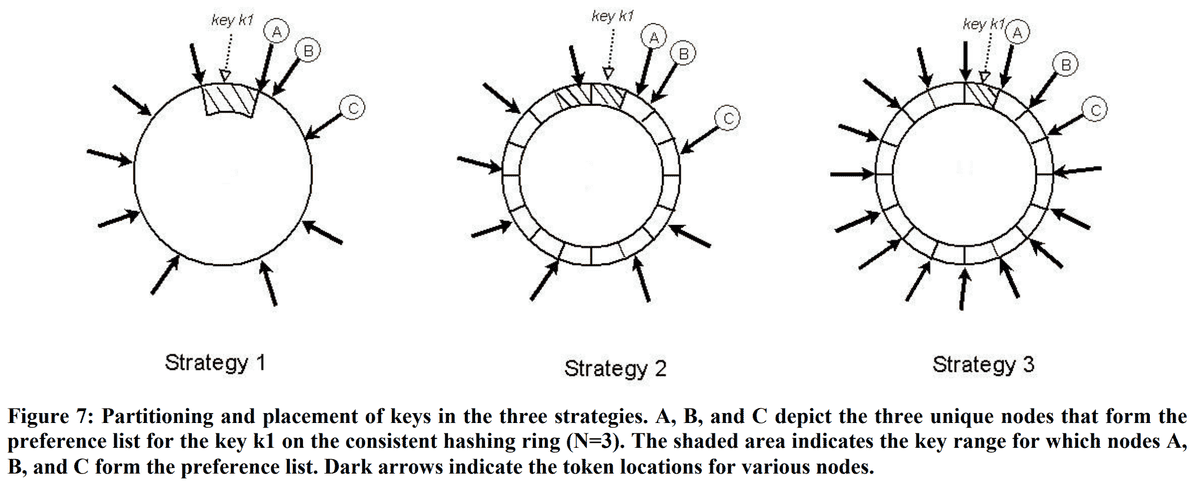
Strategy 1: T random tokens per node and partition by token value
数据空间随机生成 T 个 Token,相邻两个 Token 之间的数据为一个 partition。
缺点:
- 新节点加入时,相邻节点需要遍历所有数据才能找到需要迁移给新节点的
- 节点变更时,由于 partition 发生了变化,所有受影响的节点的 Merkle tree 都需要重新构建
- 备份/恢复数据代价太大。
Strategy 2: T random tokens per node and equal sized partitions
Hash 空间被分成 Q 个相等的 partition,每个 Node 随机分配 T 个 token,对于 S 个节点存在:Q >> N & Q >> S * T。
相比 Strategy 1 优点:
- 解耦了 key -> partition 和 partition -> node 的映射
- 支持了动态的变更 partition -> node 的映射关系
Strategy 3: Q/S tokens per node, equal-sized partitions
相比 Strategy 2,每个节点分配 Q/S token
优点:
- 可以更快的启动/恢复:partition 大小固定,一个 partition 可以整个迁移。
- 易于备份:partition 大小固定,可以独立备份/恢复。
缺点:
- 更改节点成员关系需要协调,以便保留分配所需的属性。
Divergent Versions:When and How Many?
数据项的不同版本出现在两个场景中
- 当系统面临诸如节点故障、数据中心故障和网络分区等故障场景时。
- 当多个 client 并发的更新一个数据,而处理更新请求的 coordinator 为不同的节点。
对返回到购物车服务的版本数进行了24小时的分析,多版本发生的概率非常小。在此期间:
- 99.94%的请求只看到一个版本
- 0.00057%的请求有两个版本
- 0.00047%的请求看到了3个版本
- 0.00009%的请求看到了4个版本。
经验表明,多版本的形成更多是因为并发更新,而不是系统故障,而并发更新更多的是有些 robots,非人工主动操作。
Client-driven or Server-driven Coordination
Server-driven:由负载均衡组件将请求路由到相应节点。Coordinator 负责处理 Client 的 put/get 请求。对于读请求,任何节点都可以作为 coordinator。对于写请求,因为更新数据时需要生成新的 version stamp,只有 preference list 中的前 N 个节点可以作为 coordinator。
Client-driven:Client 本地存储集群节点视图,在 Client 端选择请求的 coordinator,直连相应的节点进行 put/get。优点是节省了负载均衡系统的转发,缺点是无法及时感知到成员信息的变更。
99.9%读延迟(ms) | 99.9%的写延迟(ms) | 平均读取延迟(ms) | 平均写延迟(ms) | |
Server-driven | 68.9 | 68.5 | 3.9 | 4.02 |
Client-driven | 30.4 | 1.55 | 1.9 |
Balancing background vs foreground tasks
除了响应 put/get 请求的前台任务,每个节点还有一些后台任务,副本同步、数据的迁移等。优先级 前台任务 > 后台任务。
admission controller 通过监控前台任务的执行情况来评估有多少时间片可以用于执行后台任务。主要监控以下几方面:磁盘IO、数据库的锁竞争和事务超时、请求队列长度。
Discussion
过去两年有很多系统已经使用了 Dynamo,在可用性方面表现亮眼,没发生过数据丢失的问题,99.9995% 的请求在超时时间内成功响应。
Dynamo的主要优点是,用户可以通过配置 (N,R,W) 三个参数来根据它们的需求来对 Dynamo 进行调优。与其他存储不同,Dynamo向开发人员暴露了数据一致性、多版本数据协调的问题。一开始,大家觉得系统逻辑会变得更复杂。然而 Amazon 的平台是为高可用性而构建的,许多应用程序在设计时已经考虑了可能出现的不同故障模式、数据不一致。因此,将此类应用程序移植到 Dynamo 非常简单。
Dynamo 使用 gossips 协议来在集群中传播节点信息,对于数百个节点组成的系统可以很好的工作,
将这样的设计扩展到运行成千上万个节点并不简单,维护路由表的开销会随着系统的大小而增加。
暂无评论...